
A la découverte de Spark Streaming
| Il existe plusieurs systèmes de calculs distribués permettant de traiter une volumétrie importante de données: Big Data, le tout en temps réel. L’une des solutions les plus connus c’est Spark. |
Apache Spark
Apache Spark est un framework open source totalement écrit en Scala, permettant le traitement de données volumineuses à travers des calculs distribués en mémoire.
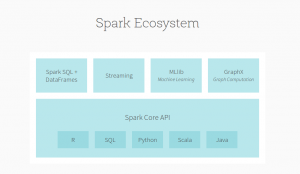
L’écosystème de Spark se compose de Spark Core qui est le projet principal effectuant les divers calculs distribués et puis on retrouve un ensemble de modules ajoutant des nouvelles fonctionnalités :
- Spark Sql permettant le traitement de données structurées en utilisant un langage très similaire à SQL,
- GraphX permet l’exploration des graphes,
- MLib qui contient tout une bibliothèque d’algorithme de Machine Learning pour réaliser de la classification, de la recommandation…
- Spark streaming pour l’analyse en temps réel de gros volumes de données.
Du temps réel
Spark excelle dans l’analyse en temps réel grâce au module Spark Streaming.
Spark Streaming permet ainsi d’analyser des flux de données en temps réel. Inversement à Apache Storm qui gère le flux de données d’un coup (one at a time), Spark Streaming découpe le flux de données en plusieurs petits batches à intervalle de temps régulier avant de les traiter. Il faut noter que avec Storm Trident, il possible aujourd’hui de faire du micro-batch sur un flux de données (stream) en s’assurant d’avoir une source fiable alors que Spark Streaming gère très bien le cas d’une source de données avec des échecs.

DStream
Spark Streaming se base sur une abstraction appelé DStream pour Discritized Stream. DStream représente un batche de RDD (Resilient Distributed Datasets).
RDD est l’abstraction de collection utilisé par Spark pour le traitement des données et sur laquelle on réalise les diverses opérations de calcul que ce soit des transformations tel que :
- map() transformer un élément en un autre élément,
- flatmap() découper un élément en plusieurs autres éléments,
- filter() filtrer les éléments en ne gardant que ceux qui vérifient la condition spécifiée,
- reduceByKey() agréger des éléments entre eux,
- mapToPair() création d’un tuple clé-valeur pour chaque élément,
- ..
Ou des actions tel que :
- count() calcul des éléments finaux,
- collect() retourner les éléments sous forme d’une collection Java,
- saveAsTextFile() pour sauvegarder les résultats dans un fichier texte,
- cache() pour sauvegarder le résultat en mémoire,
- persist() pour sauvegarder le résultat sur disque,
- ..
Data sources
Spark Streaming s’intègre avec plusieurs sources de données tel que :
- Apache Kafka: un système de messaging distribué,
- Apache Flume: un système de collecte de logs,
- Twitter: en récupérant les tweets avec l’API Twitter de streaming.
- TCP sockets.
Spark Streaming propose aussi une intégration pour les autres data sources qui ne bénéficient pas d’une intégration prédéfinie. Il suffit d’implémenter la classe Receiver.
Multi-langage
Apache Spark supporte plusieurs langages: Scala, Java, Python et R.
Pour les exemples suivants, le langage utilisé est Scala.
Scala est un langage de programmation multi-paradigme qui s’intègre avec les paradigmes de programmation objet et de programmation fonctionnelle. Il se caractérise par un typage statique, l’inférence de type ou les conversions implicites qui rendent l’utilisation d’Apache Spark plus simple.
Exemple: word count
L’objectif de cet exemple est de calculer le nombre d’occurrence de mots en temps réel.
La première étape est d’initialiser le contexte Spark Streaming:
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf()
.setAppName(“myFirstApp”)
.setMaster(local[*])
val ssc = new StreamingContext(conf, Seconds(2))
On crée le contexte Spark en précisant le nom de notre application ainsi que le cluster manager. Dans cet exemple, le mode de lancement de Spark est en standalone. C’est la solution la plus simple qui se base sur Akka pour les échanges et sur Zookeeper pour la haute disponibilité du nœud master. L’exécuteur a été initialisé avec [*] ce qui veut dire autant de thread que possible sachant qu’il faudra toujours avoir au moins deux threads : un pour la lecture des données et un autre pour le traitement des données.
Spark peut faire appel à d’autres gestionnaires de cluster tel que Mesos ou YARN.
Après l’initialisation du contexte Spark, on initialise le spark streaming context à partir de ce dernier et on précise la période de streaming qui est de 2 secondes pour cet exemple.
L’étape suivante est de définir le flux de données à utiliser. Il existe plusieurs possibilités de flux de données. Ici, on va présenter quelques types de flux pour notre exemple simple : le calcul du nombre d’occurrence de chaque mot d’un texte.
Socket stream
Les sockets sont des connecteurs réseau qui permettent d’utiliser le protocole TCP ou UDP.
Ici, ça sera plutôt le protocole TCP (Transmission Control Protocol). L’idée est de récupérer le flux de données en temps réel. Les données récupérées sont sous la forme d’un texte.
L’idée ici est de calculer le nombre d’occurrence de chacun des mots toutes les deux secondes.
val lines = ssc.socketTextStream(host, port, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(“ “))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
Après avoir décrit les actions à faire pour le flux, on démarre le streaming en appelant l’action ssc.start(). Ensuite, le traitement est lancé sur des threads différents. On peut arrêter le thread principal soit en précisant un événement particulier ou en attendant la fin de l’exécution ssc.awaitTermination().
Kafka stream
Kafka est système de messagerie distribué. Il a pour but de conserver les messages de façon temporaire (comme pour un système de Queuing) permettant de garantir, lors de forts pics de charge, l’intégrité du message. Je vous conseille de lire l’article dessus qui est inclus dans ce numéro pour avoir plus d’informations.
// Create direct kafka stream with brokers and topics
val kafkaParams = Map[String, String](“metadata.broker.list” -> brokers)
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
// Get the lines, split them into words, count the words and print
val lines = messages.map(_._2)
val words = lines.flatMap(_.split(“ “))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
ssc.awaitTermination()
Pour écouter les messages, il faut tout d’abord configurer kafka : spécifier les brokers et la liste des topics. Ensuite, pour chaque message, on récupère les mots et on calcule le nombre d’occurrence de chaque mot.
Custom receiver
Si on souhaite récupérer des données dont il n’existe pas d’intégration directe dans Spark Streaming, on peut créer notre propre Receiver.
object CustomReceiver {
val sparkConf = new SparkConf().setAppName(“CustomReceiver”)
val ssc = new StreamingContext(sparkConf, Seconds(2))
val lines = ssc.receiverStream(new CustomReceiver(myHostname, port))
val words = lines.flatMap(_.split(“ “))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
L’initialisation est la même que précédemment sauf que l’on fait appel à la méthode receiverStream de Spark Streaming qui prend en paramètre le Custom receiver. Le Custom receiver nous renvoie comme résultat des lignes de texte sur lesquelles on applique les mêmes transformations que précédemment pour obtenir le nombre d’occurrence des mots.
Si on regarde de plus près le Custom Receiver:
class CustomReceiver(host: String, port: Int)
extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) with Logging {
def onStart() {
new Thread(“Socket Receiver”) {
override def run() { receive() }
}.start()
}
def onStop() {
}
}
La classe Custom Receiver étend l’interface Receiver fournit par Spark Streaming et qui contient les deux méthodes : start() et stop().
private def receive() {
var socket: Socket = null
var userInput: String = null
try {
socket = new Socket(host, port)
val reader = new BufferedReader(
new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8))
userInput = reader.readLine()
while(!isStopped && userInput != null) {
store(userInput)
userInput = reader.readLine()
}
reader.close()
socket.close()
logInfo(“Stopped receiving”)
restart(“Trying to connect again”)
} catch {
case e: java.net.ConnectException =>
restart(“Error connecting to “ + host + “:” + port, e)
case t: Throwable =>
restart(“Error receiving data”, t)
}
}
Dans la méthode start(), on précise la source de données qui sera utilisé. Ici, dans la méthode receive(), on lit les données d’un InputStream et on sauvegarde chacune des lignes lues pendant la durée du batche qui est de 2 secondes.
Les lignes récupérés via le Custom Receiver seront traitées et un nouveau batche va aussitôt se lancer pour récupérer des nouvelles lignes et les analyser et ainsi de suite.
DataFrames
En plus la lecture de flux de données en temps réel, Spark Streaming peut aussi récupérer un flux de données et le transformer pour le stocker dans une base de données. Dans ce cas, on initialise en plus un Spark SQL context en se basant sur Spark Context et on crée un Spark SQL Dataframe.
val lines = ssc.socketTextStream(hostname, port, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(“ “))
// Convert RDDs of the words DStream to DataFrame and run SQL query
words.foreachRDD((rdd: RDD[String], time: Time) => {
// Get the singleton instance of SQLContext
val sqlContext = SQLContextSingleton.getInstance(rdd.sparkContext)
import sqlContext.implicits._
// Convert RDD[String] to RDD[case class] to DataFrame
val wordsDataFrame = rdd.map(w => Record(w)).toDF()
// Register as table
wordsDataFrame.registerTempTable(“words”)
// Do word count on table using SQL and print it
val wordCountsDataFrame =
sqlContext.sql(“select word, count(*) as total from words group by word”)
println(s”========= $time =========”)
wordCountsDataFrame.show()
})
ssc.start()
ssc.awaitTermination()
On transforme ainsi les données en Dataframe et ensuite on effectue le calcul du nombre d’occurrence en faisant appel à une simple requête SQL.
Attention à un détail, le Spark SQL context doit être un singleton :
/** Lazily instantiated singleton instance of SQLContext */
object SQLContextSingleton {
@transient private var instance: SQLContext = _
def getInstance(sparkContext: SparkContext): SQLContext = {
if (instance == null) {
instance = new SQLContext(sparkContext)
}
instance
}
}
Le cas d’usage peut être mis en place dans le cas ou on a besoin de récupérer des informations et les sauvegarder pour servir dans des traitements ultérieurs.
Apache Flume
Apache Flume est un système distribué qui permet d’aggréger un grand volume de données en temps réels. Les données peuvent être des logs ou des événements.
On change d’exemple précédent qui était le calcul du nombre d’occurrence d’un mot pour calculer le nombre d’événement reçus. Les étapes initiales sont les mêmes: on initialise un context spark et spark streaming comme précédemment en précisant l’intervalle de batche.
// Create the context and set the batch size
val sparkConf = new SparkConf().setAppName(“FlumeEventCount”)
val ssc = new StreamingContext(sparkConf, Milliseconds(2000))
// Create a flume stream
val stream = FlumeUtils.createStream(ssc, host, port, StorageLevel.MEMORY_ONLY_SER_2)
// Print out the count of events received from this server in each batch
stream.count().map(cnt => “Received “ + cnt + “ flume events.” ).print()
ssc.start()
ssc.awaitTermination()
Ensuite, on fait appel à FlumeUtils pour créer le flux de données et réaliser le traitement souhaité : le calcul du nombre d’événements reçus.
Cas d’utilisation
Spark Streaming est utilisé dans différents cas:
- Streaming ETL: les données sont nettoyées et agrégées avant d’être sauvegardées
- Triggers: détection des comportements suspects en temps réel (fraude) et enclencher les actions nécessaires
- Enrichissement des données: les données temps réel sont enrichies avec d’autres informations afin de compléter l’analyse
- Apprentissage continu et session: regroupement et analyse des événements lié à une session active (authentification à un site web) et potentiellement utiliser les informations pour mettre à jour les models de machine learning.
Conclusion
Spark Streaming est l’une des meilleures solutions actuelles pour le traitement de flux de données en temps réel et en continu. La prise en main est très facile car Spark Streaming propose déjà l’intégration de plusieurs types de sources de données.