
Premier essai avec les pipelines de Jenkins 2
| Un nouveau projet implique de nouveaux essais, ça tombe bien j’avais justement envie d’essayer les pipelines de Jenkins 2 et le test continu des non régressions de performance ! |
Prenons Jenkins2, Docker, Gatling, et Maven, mélangeons tout ça et voyons ce qu’il est possible de créer.
Cas d’usage: tests continu de non régression de performances
Cela fait longtemps que j’avais envie de mettre en place sur un projet, des tests automatisés de non régressions de performance. L’idée est de s’assurer, avec des micro-bench, que les performances des parties critiques de l’application ne baissent pas au fur et à mesure des développements.
L’objectif est :
- D’utiliser les sources les plus fraîches possibles
- De démarrer l’application sur un environnement d’intégration
- De passer les tests de performances avec Gatling
- D’alerter, surveiller la non régression de performances
Pourquoi Jenkins ?
La première raison est que je connais très bien Jenkins pour l’avoir utilisé pour beaucoup de tâches différentes. Quand j’essaye une nouveauté je suis du genre prudente : pas trop de nouvelles choses à la fois. Jenkins a l’avantage de posséder un éco-système de plugin très fourni, et le plugin qui m’intéresse plus particulièrement est le plugin Gatling qui permet d’agréger les résultats de plusieurs builds successifs. Et puis cela fait un moment que j’entends parler de ces fameux pipelines, j’avais très envie de les tester.
Pourquoi Gatling ?
Gatling est un outil open source permettant de faire des tests de performance. Il a la particularité d’être fait pour les développeurs : les scénarios à utiliser pour les tests de performance sont écrit en Scala.
Il est parfaitement bien intégré à Maven, ce qui permet de l’inclure dans le cycle de vie de l’application assez facilement. Et cerise sur le gâteau, les résultats sont disponible nativement en HTML avec un ensemble de graphes assez bien faits.
Qu’est-ce qu’un « pipeline » ?
En quelques mots, un pipeline permet d’enchainer des tâches en donnant un sens fonctionnel à chaque tâche. Basiquement un pipeline pourrait être remplacé par un gros script shell, l’inconvénient est lorsque le build échoue, cela s’avère plus complexe pour en trouver la cause. Un autre avantage c’est que des tâches sans aucune dépendance peuvent être réalisées en parallèle.
Pré-requis
J’ai simplifié beaucoup d’étapes, nous avons la chance chez Worldline d’avoir un cloud privé qui peut être utilisé pour des démonstrations ou des Proof Of Concept. C’est un environnement sur lequel je peux créer des VM en toute autonomie, dans la limite du raisonnable en terme de ressources (pas de vrai tests de performance). Le bon côté c’est que ça permet de faire du devops à fond : j’ai aussi bien écrit du code dans l’application que monté des volumes et fait des “yum install”. J’ai donc la maîtrise complète de toute la chaîne : root sur la VM, et admin sur Jenkins.
J’ai testé l’ensemble sur un CentOS 7.3, ayant installé:
- docker, docker-compose
- Java, Maven
- Jenkins 2
- configuration par défaut
- plugin xunit
- plugin Gatling
- plugin blue ocean (optionnel)
Comment ça se créé un pipeline Jenkins ?
Bon Jenkins nous embrouille un peu, en proposant deux langages de pipeline « Declarative pipeline » vs « Scripted pipeline ». La version « Scripted » est la première a voir été créée, elle utilise directement le langage groovy et permet une très grande flexibilité étant donné que c’est un langage de programmation. Par contre je trouve que pour débuter c’est un peu difficile, surtout si comme moi vous n’avez jamais écrit de groovy.
https://jenkins.io/doc/book/pipeline/syntax/#compare
La version « Declarative » est plus simple d’utilisation, mais moins extensible car basée sur des mots clefs. J’ai cru comprendre qu’on pouvait aussi écrire des parties en groovy dans la version “Declarative” mais je n’en ai pas eu besoin, donc je n’ai pas testé. Comme dans un premier temps je pensais utiliser massivement les scripts shell linux, mon choix s’est porté sur la syntaxe « Declarative ».
La base c’est qu’il faut décrire les actions à exécuter, Jenkins propose deux choix : soit écrire le script directement dans l’interface graphique de Jenkins, soit dans un Jenkinsfile placé par défaut à la racine du projet. Comme j’ai eu rapidement besoin des sources du projet, j’ai opté comme préconisé dans la documentation de référence pour le Jenkinsfile dans le git du projet.
Il reste ensuite à créer un job de type pipeline et indiquer le SCM dans lequel se trouve le Jenkinsfile. C’est très bien détaillé (en anglais) sur la page de Getting started :
Voici un Jenkinsfile basique en syntaxe « Declarative » :
pipeline { (1)
agent any (2)
stages {
stage("Prepare"){ (3)
steps{
sh '''
echo "Prepare continuous delivery env"
'''
}
}
stage ("Build"){
steps {
sh '''
echo "Building app"
'''
}
}
}
(1) agent any: peut s’exécuter sur n’importe quel worker Jenkins, ici il n’y en a qu’un.
(2) stage : ce sont les étapes auxquelles on donne un petit nom, le nom se retrouve ensuite sur l’interface graphique des pipeline
(3) step : le détail des actions à effectuer, la plupart du temps des scripts shell dans mon cas
Petit détail que je n’avais pas remarqué au début : il y a deux façons d’écrire les scripts shell, ligne par ligne :
sh ' echo "mon script shell sur une seule ligne" '
sh ' echo "si j’ai une seconde ligne elle vient ici" '
sh ' echo "quand j’en ai une troisième ça commence a faire beaucoup" '
ou alors par bloc entier, ce qui est nettement plus lisible quand on commence à écrire beaucoup de shell:
sh '''
echo "ici j’écris directement"
echo "les instructions les unes après les autres"
'''
Etape 1 : les sources fraîches
C’est le plus facile, nous sommes partis dans l’équipe sur un projet mono-git donc il suffit mettre le Jenkinsfile à la racine du projet, et d’indiquer l’url du git sur l’administration du job. Il y a ensuite une surveillance du git qui lance la pipeline dès qu’un merge est effectué dans la branche principale « master ». A noter que l’équipe fonctionne en « branch feature », donc lorsqu’il y a un merge dans master le code a été relu et le pipeline d’intégration continue (tests unitaires et tests d’intégrations) est passée avec succès.
J’ai un crédo : sans notifications les automatisations sont inutiles. Elles se perdent au fond du placard comme ce dernier carton de déménagement qui n’a jamais été déballé. En général quand on le retrouve c’est trop tard, on a déjà remplacé la plupart des choses.
Comme la plateforme a pour objectif à la fois de valider la non régression de performance, mais aussi de permettre une recette interne à l’équipe, le pipeline utilise un channel dédié mattermost (une alternative opensource a slack) pour informer l’équipe des redémarrages en cours. Le script de notification est un simple curl qui poste le message en paramètre sur le mattermost de l’équipe.
#!/bin/bash
# Post mattermost notification on ci channel
# param: message to post
if \[\[ -z $1 \]\]
then
echo "Param MESSAGE is needed, please give it."
echo "Usage : $0 <MESSAGE>"
exit 1;
fi
MESSAGE="$1"
TIMEOUT\_CURL=30
MATTERMOST\_HOOK=https://mattermost.tateam.com/hooks/xxxxxxxxxxxx
FULL\_MESSAGE="\[${JOB\_NAME}\] ${MESSAGE}"
curl -m ${TIMEOUT\_CURL} -s -i -k -XPOST --data 'payload={"username":"Jenkins","text":"'"${FULL\_MESSAGE}"'"}' ${MATTERMOST\_HOOK}
A noter que la variable JOB_NAME est directement celle mise à disposition par Jenkins. Elle permet de savoir d’où viennent les notifications.
L’avantage de mattermost par rapport aux e-mails, c’est que les personnes choisissent de souscrire au channel, et peuvent s’y désinscrire à tout moment ou régler les notifications. Ça peut donner des messages sympathiques comme :
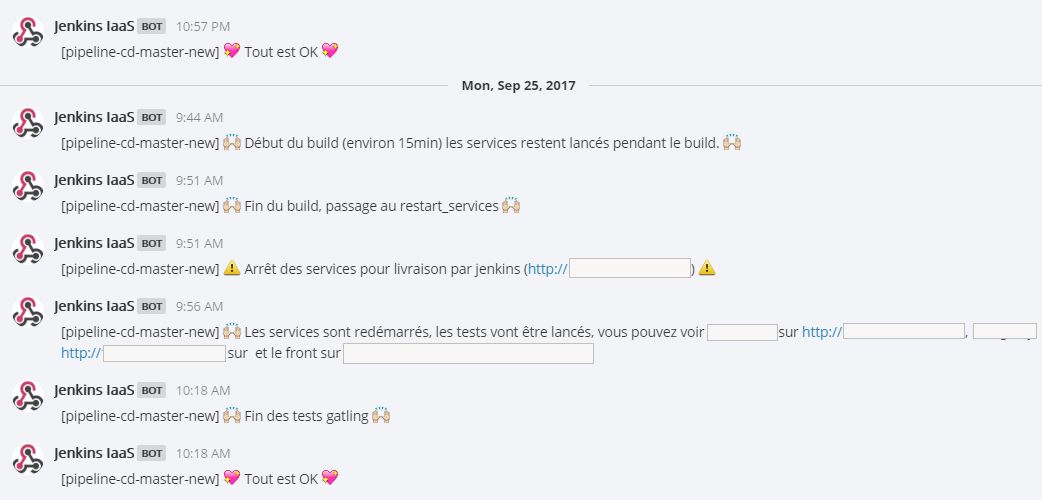 Je ne sais pas si je préfère les petits cœurs ou les liens directement cliquables…
Je ne sais pas si je préfère les petits cœurs ou les liens directement cliquables…
Etape 2 : lancer l’application
Il y a un docker-compose pour le développement en local, donc le plus simple est de l’utiliser aussi pour lancer les services sur la plateforme de déploiement continu. Nous ne publions pas systématiquement les images docker a chaque merge sur master, mais seulement pour les releases.
Les images docker sont construites en local de la VM via le plugin docker-maven-plugin :
stage ("Build"){
steps {
sh '''
./common/scripts/notification.sh ":raised\_hands: Début du build (environ 15min) les services restent lancés pendant le build. :raised\_hands:"
MY\_SERVICES="service1 service2 front1 front2"
MVN\_CMD="mvn package docker:build -DskipTests"
for service in \`echo ${MY\_SERVICES}\` ; do echo "Building service $service"; cd "$service"; ${MVN\_CMD}; cd - ;done;
./common/scripts/notification.sh ":raised\_hands: Fin du build, passage au restart\_services :raised\_hands:"
'''
}
}
Un second objectif de la plateforme de déploiement continue est d’avoir la dernière version de l’application disponible pour le suivi de l’avancement par le chef de projet ou la réalisation d’une recette interne. Les services sont donc arrêtés le moins possible, juste avant le redémarrage pour prendre en compte la nouvelle version :
stage("Stop previous env"){
steps{
sh '''
./common/scripts/notification.sh ":warning: Arrêt des services pour livraison par jenkins :warning:"
cd docker-compose; docker-compose stop; docker-compose rm -f
'''
}
}
stage("Start services"){
steps{
sh '''
cd docker-compose
docker-compose up -d
'''
}
}
A tiens, premier mur : comment savoir si mes services sont prêt pour pouvoir lancer mes tests Gatling ? Un sleep suffisamment long devrait faire l’affaire, mais bon ce n’est pas sûr non plus. Et puis ça peut être intéressant de savoir quel service exactement n’a pas pu se lancer en cas d’échec. Allez un petit script, y a que ça de vrai :
#!/bin/bash
# Check if micro service in param is up
# i.e. the HTTP result code is 200 for URL in param ()
# Exit 0 if ok, 1 else
if \[\[ -z $1 \]\]
then
echo "Param URL is needed, please give it."
echo "Usage : $0 <URL to check>"
exit 1;
fi
URL\_TO\_CHECK=$1
TIMEOUT\_CURL=30
HTTP\_STATUS=\`curl -m ${TIMEOUT\_CURL} -sL -I ${URL\_TO\_CHECK} | grep -c "200 OK"\`
if \[\[ $HTTP\_STATUS == "1" \]\]
then
echo "Service OK ${URL\_TO\_CHECK}"
exit 0
else
echo "Service Not OK ${URL\_TO\_CHECK}"
exit 1
fi
Et puis une étape de vérification des services :
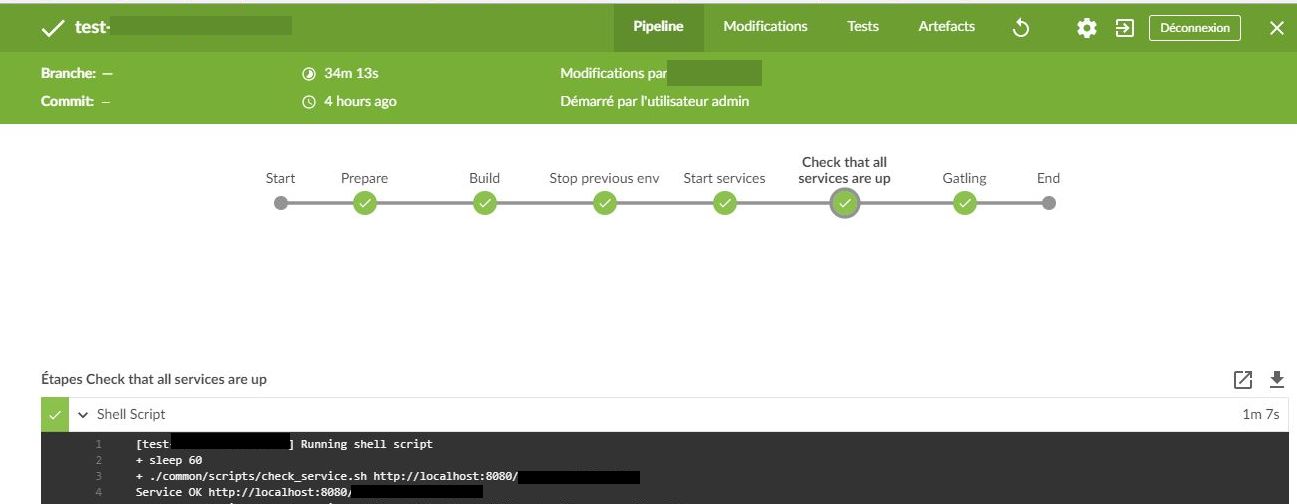
stage("Check that all services are up"){
steps{
retry(10){
sh '''
sleep 60
./common/scripts/check\_service.sh http://localhost:8080/ping
./common/scripts/check\_service.sh http://localhost:8081/ping
./common/scripts/check\_service.sh http://localhost:80/
'''
}
}
}
Avez-vous vu apparaître le bloc « retry » ? C’est très pratique, le script va essayer jusqu’à 10 fois de voir si tous les services sont disponibles. Donc au mieux si tout démarre en moins d’une minute l’étape est passée rapidement, sinon j’ai jusque 10 minutes de délai pour des lenteurs réseau, du vol de CPU par une VM voisine ou autres joies des environnements mutualisés.
Etape 3 : Tout est prêt, il est temps de vérifier la performance
Enfin, tout est prêt pour pouvoir valider les performances de l’application.
stage("Gatling"){
steps{
sh '''
./common/scripts/notification.sh ":raised\_hands: Les services sont redémarrés, les tests vont être lances"
cd service1; mvn gatling:test
cd ../service2; mvn gatling:test
cd ../service3; mvn gatling:test
'''
gatlingArchive()
sh './common/scripts/notification.sh ":raised\_hands: Fin des tests gatling :raised\_hands:" '
}
}
Les tests Gatling sont lancés avec maven, en version micro bench : avec peu d’utilisateurs (je rappelle que ce n’est pas une plateforme dédiée aux tests de performances). Le but étant de pouvoir constater si le développement d’une fonctionnalité apporte une soudaine lenteur.
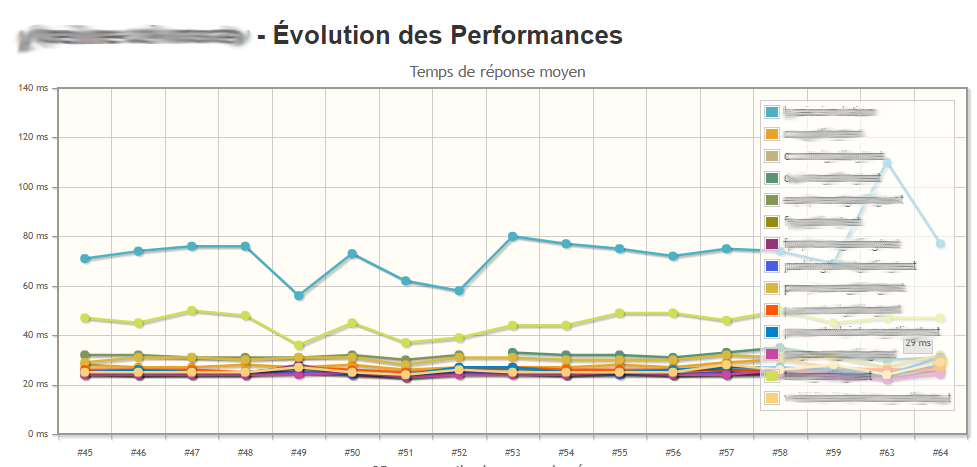
La partie gatlingArchive() permet de chercher dans le workspace des résultats de tests Gatling et de les archiver.
C’est là la faiblesse des scripts « Declarative » de Jenkins, il est très difficile de trouver s’il y a possibilité ou pas de faire appel à un plugin et comment. En cherchant sur qwant (google c’est pareil) on tombe sur une pauvre page, sans exemple ni rien (j’ai fait un screenshot au cas où ils auraient la bonne idée de faire un peu plus de documentation) :
Le plugin Gatling permet en plus de l’archivage des résultats classiques de Gatling, d’avoir l’agrégation de 3 métriques, à condition de conserver quelques builds d’historique. Voici par exemple l’historique des temps de réponse moyen par scénario:
C’est la fin
Et non ! Et si tout ça plante en plein milieu, qu’est-ce qu’il se passe ? Pas grand-chose pour l’instant. Et là en cherchant un peu j’ai trouvé qu’on pouvait déclarer des post actions après la liste de stages{} :
pipeline {
stages{
stage("Build"){…}
…
}
post {
always {
sh 'echo "---- THE END ----"'
}
success {
sh './common/scripts/notification.sh ":sparkling\_heart: Tout est OK :sparkling\_heart:" '
}
failure {
sh './common/scripts/notification.sh ":broken\_heart: Il y a eu un problème sur la pipeline, merci de consulter les logs sur jenkins http://monjenkins:8080 :broken\_heart:" '
}
}
}
Maintenant l’équipe est prévenue si quelque chose se passe mal sur la plateforme de déploiement continu.
Vanilla Jenkins vs Blue Ocean
Voici la représentation des pipelines sous Jenkins. J’ai été très surprise au début, j’avais vu passer des tweet beaucoup plus vendeur que ça :

En fait il existe un plugin « Blue ocean » qui permet de changer complètement l’interface graphique de Jenkins. Je l’ai testé et c’est beaucoup plus esthétique
Par contre je n’ai pas trouvé de fonctionnalités supplémentaires, du coup c’est très rare que je l’utilise pour l’instant.
Les trucs auxquels je n’avais pas pensé
Une fois la livraison continue mise en place, ainsi que le passage des micro benchs à chaque merge de master, il n’est plus possible de modifier des choses ou ajouter des choses dans la pipeline sans casser le build pour toute l’équipe. Je me suis vite rendue compte qu’en fait la plateforme actuelle était une “production” pour l’équipe et qu’il me fallait une seconde plateforme iso de test.
Autre chose évidente à laquelle je n’avais pas pensé c’est que comme tout est lancé en local de la VM, il ne faut pas qu’il y ai 2 builds en même temps, sinon on peut se retrouver a voir un redémarrage de l’application au milieu des tests Gatling. La solution est assez simple, il suffit de cocher la case “Do not allow concurrent build”.
Enfin dernière chose, lancer tous les services, le Jenkins et la base de données même peu remplie sur une seule et même machine demande quand même pas mal de puissance. Mes premiers essais ont été réalisé sur un VM de taille “normale” (8Go RAM + 2 cpu / 2 GHz) mais c’était un peu limite. Après migration sur une VM plus “grosse” (16Go RAM + 4 cpu / 2 GHz) la plateforme est devenue beaucoup plus stable et le temps complet (du build jusqu’à la fin des tests Gatling) a été divisé par 2 !
Pour aller plus loin
Pour l’instant les tests de performances sont lancés et les résultats ainsi que la tendance sont consultable. Il manque encore l’étape d’alerte en cas de régression de performances: soit un message sur mattermost, soit carrément un fail du build. Gatling permet de créer des scénarios fonctionnels et de configurer des seuils de temps de réponse à ne pas dépasser donc ça devrait pouvoir se faire assez facilement. Comme les services vitaux de l’application ne sont pas encore identifiés, il n’est pas encore possible de configurer les seuils pour l’instant.
Dans un monde idéal, il faudrait que les tests de non régression de performance soient passés avant la validation de la merge request. Mais ça demande beaucoup plus d’effort de mise en place: ça voudrait dire que pour toutes les branches il faut lancer les services et passer les tests Gatling. Rien n’est impossible mais l’effort de mise en place et de maintenance est beaucoup plus élevé.
Il y a une nouvelle fonctionnalité toute neuve que je n’ai pas encore testé: la parallélisation des tâches. Dans le cas ou tout est lancé sur une seule VM, je ne suis pas sûre que ça fasse gagner beaucoup de temps: la compilation java par exemple consomme une grande quantité de CPU, donc paralléliser la compilation sur une seule et même machine ne permettrait pas de gagner du temps. Par contre sur une infrastructure de Jenkins beaucoup plus évoluée, avec un pool de runners (machines ne faisant qu’exécuter les jobs, l’orchestration restant maîtrisée par le Jenkins maître) le parallélisme a plus de sens.
Merci d’avoir lu jusqu’ici, et bon tests !