
Getting started with Spark in practice
| Some months ago, we, Sam Bessalah and I organized a workshop via Duchess France to introduce Apache Spark and its ecosystem. |
This post aims to quickly recap basics about the Apache Spark framework and it describes exercises provided in this workshop (see the Exercises part) to get started with Spark (1.4), Spark streaming and dataFrame in practice.
If you want to start with Spark and come of its components, exercises of the workshop are available both in Java and Scala on this github account. You just have to clone the project and go! If you need help, take a look at the solution branch.

With MapReduce/Hadoop frameworks the way to reuse data between computations is to write it to an external stable storage system like HDFS. And it’s not very effective when you iterate because it suffers from I/O overhead.
If you want to reuse data, in particular, if you want to use Machine Learning algorithms you need to find a more efficient solution. This was one of the motivation behind the creation of the Spark framework: to develop a framework that works well with data reuse.
Other goals of Apache Spark were to design a programming model that supports more than MapReduce patterns, and to maintain its automatic fault tolerance.
In a nutshell Apache Spark is a large-scale in-memory data processing framework, just like Hadoop, but faster and more flexible.
Furthermore Spark 1.4.0 includes standard components: Spark streaming, Spark SQL & DataFrame, GraphX and MLlib (Machine Learning libraries). And these frameworks can be combined seamlessly in the same application.
Here is an example on how to use Spark and MLlib on data coming from an accelerometer.
RDD
Spark has one main abstraction: Resilient Distributed Datasets or RDDs.
An RDD is an immutable collection partitioned across the nodes of the cluster which can be operated on in parallel.
You can control the persistence of an RDD:
- RDDs can be stored in memory between queries, if you need to reuse it (improve the performances in this way)
- you can also persist an RDD on disk
RDDs support two types of operations (transformations and actions):
- a transformation creates another RDD and it is lazy operation (for example: map, flatmap, filter, groupBy…)
- an action returns a value after running a computation (for example: count, first, take, collect…)
You can chain operations together, but keep in mind that the computation only runs when you call an action.
Operation on RDDs: a global view
Here is a general diagram to understand the data flow.
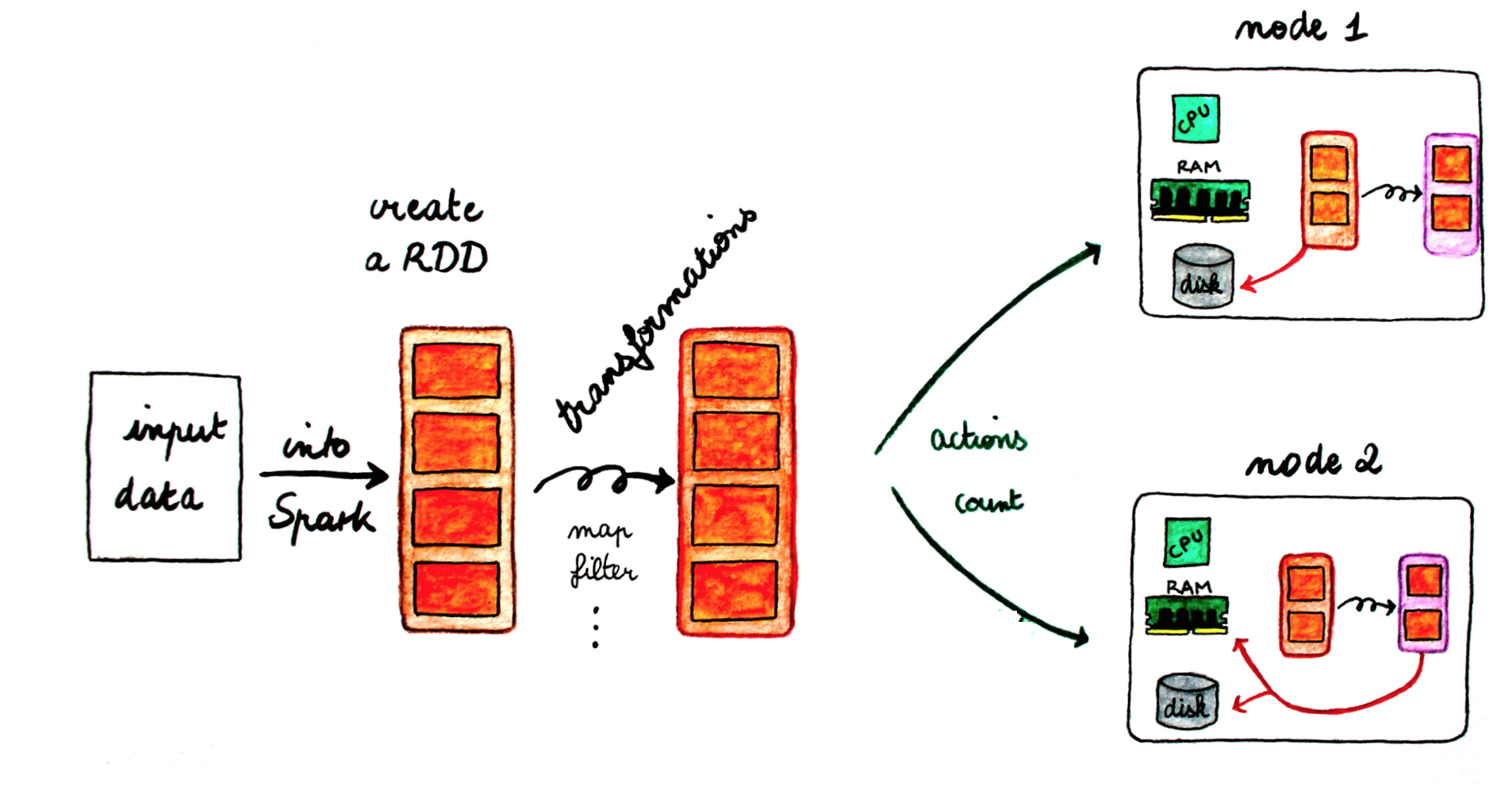
- To the left, the input data comes from an external storage. The data are loaded into Spark and an RDD is created.
- The big orange box represents an RDD with its partitions (small orange boxes). You can chain transformations on RDDs. As the transformations are lazy, the partitions will be sent across the nodes of the cluster when you will call an action on the RDD.
- Once a partition is located on a node, you can continue to operate on it.
N.B: all operations made on RDDs are registered in a DAG (direct acyclic graph): this is the lineage principle. In this way if a partition is lost, Spark can rebuilt automatically the partition thanks to this DAG.
An example: the wordcount
Here is the wordcount example: it is the “hello world” for MapReduce.
The goal is to count how many times each word appears in a file, using the mapreduce pattern.
https://gist.github.com/nivdul/0b84c5184ae42278b02f#file-wordcount
First the mapper step: we attribute 1 to each word using the transformation map.
Finally the reducer step: here the key is a word, and reduceBykey, which is an action, return the total for each word.
https://gist.github.com/nivdul/0b84c5184ae42278b02f
Exercises
In this workshop the exercises are focused on using the Spark core and Spark Streaming APIs, and also the dataFrame on data processing. The workshop is available in Java (1.8) and Scala (2.10). And to help you to implement each class, unit tests are in and there are a lot of comments.
![]()
![]()
Prerequisites
In order to get the exercises below, you need to have Java 8 installed (better to use the lambda expression). Spark 1.4.0 uses Scala 2.10 so you will need to use a compatible Scala version (2.10.x). Here we use 2.10.4. As build manager, this hands-on uses maven for the Java part and sbt for the Scala one. As unit tests library, we use jUnit (Java) and scalatest (Scala).
All exercises runs in local mode as a standalone program.
To work on the hands-on, retrieve the code via the following command line: #Scala $ git clone https://github.com/nivdul/spark-in-practice-scala.git
#Java $ git clone https://github.com/nivdul/spark-in-practice.git
Then you can import the project in IntelliJ or Eclipse (add the SBT and Scala plugins for Scala), or use sublime text for example.
If you want to use the spark-shell (only scala/python), you need to download the binary Spark distribution spark download.
# Go to the Spark directory $ cd /spark-1.4.0
# First build the project $ build/mvn -DskipTests clean package
# Launch the spark-shell $ ./bin/spark-shell scala >
Part 1: Spark core API
To be more familiar with the Spark API, you will start by implementing the wordcount example (Ex0).
After that you will use reduced tweets as the data along a json format for data mining (Ex1-Ex3). It will give you a good insight of the basic functions provided by the Spark API.
https://gist.github.com/nivdul/b41f54f02b983bc0bf05#file-reduced_tweets-json
You will have to:
- Find all the tweets by user
- Find how many tweets each user has
- Find all the persons mentioned on tweets
- Count how many times each person is mentioned
- Find the 10 most mentioned persons
- Find all the hashtags mentioned on a tweet
- Count how many times each hashtag is mentioned
- Find the 10 most popular Hashtags
The last exercise (Ex4) is a way more complicated: the goal is to build an inverted index knowing that an inverted is the data structure used to build search engines.
Assuming #spark is a hashtag that appears in tweet1, tweet3, tweet39, the inverted index will be a Map that contains a (key, value) pair as (#spark, List(tweet1,tweet3, tweet39)).
Part 2: streaming analytics with Spark Streaming
Spark Streaming is a component of Spark to process live data streams in a scalable, high-throughput and fault-tolerant way.
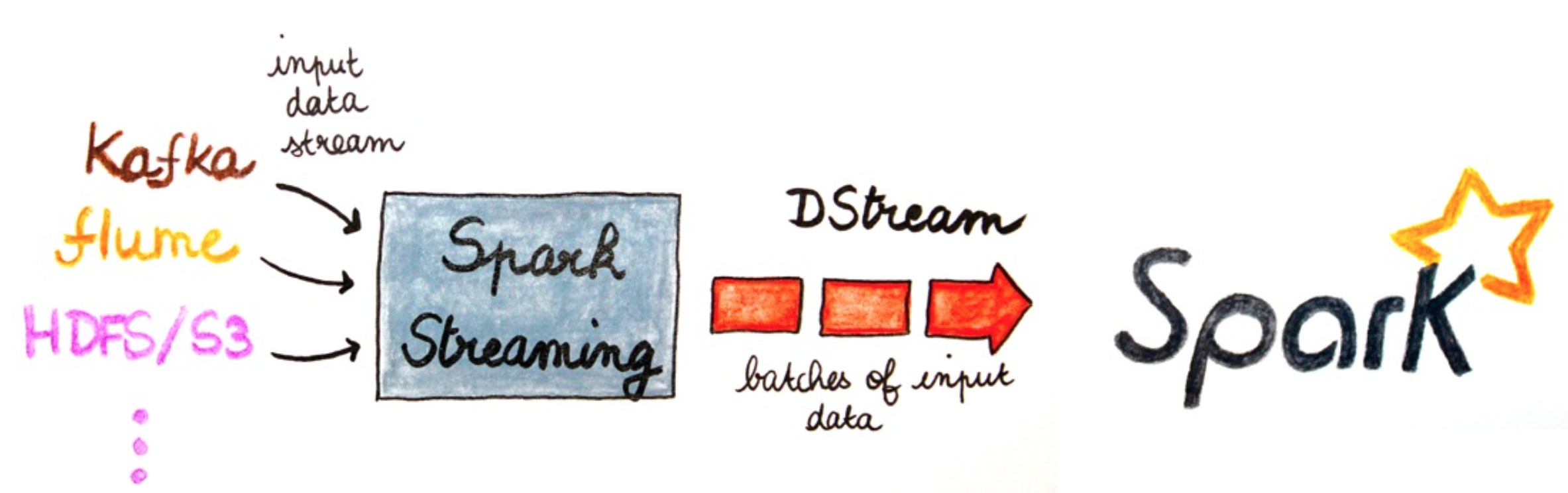
In fact Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.
The abstraction, which represents a continuous stream of data is the DStream (discretized stream).
In the workshop, Spark Streaming is used to process a live stream of Tweets using twitter4j, a library for the Twitter API.
To be able to read the firehose, you will need first to create a Twitter application at http://apps.twitter.com, get your credentials, and add it in the StreamUtils class.
In this exercise you will:
- Print the status text of the some of the tweets
- Find the 10 most popular Hashtag over a 1 minute window
Part 3: structured data with the DataFrame
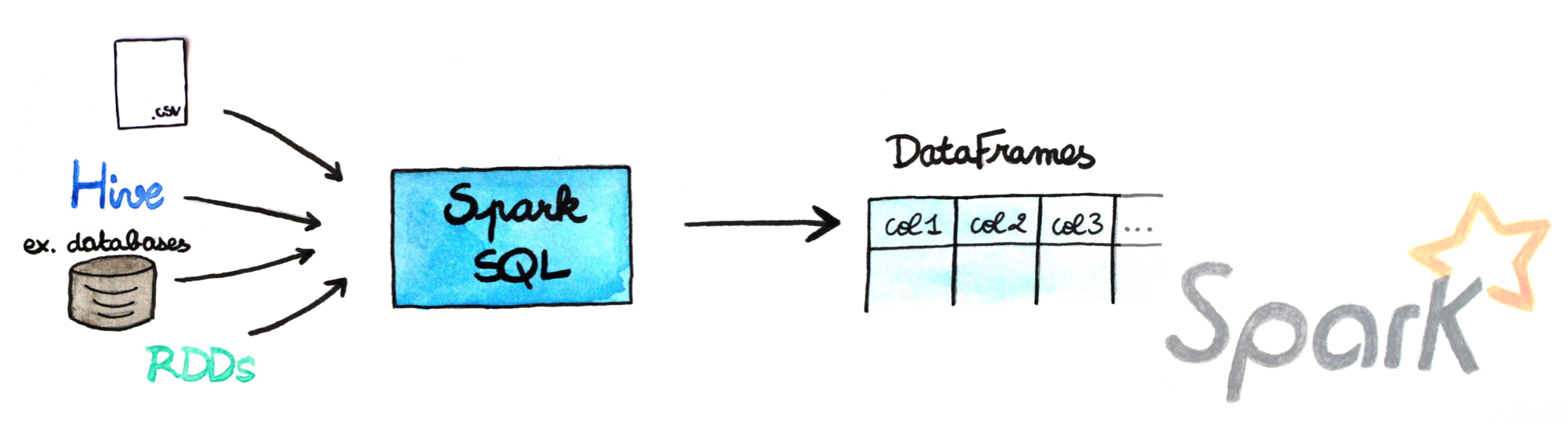
A DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. In fact, the Spark SQL/dataframe component provides a SQL like interface. So you can apply SQL like queries directly on the RDDs.
DataFrames can be constructed from different sources such as: structured data files, tables in Hive, external databases, or existing RDDs.
In the exercise you will:
- Print the dataframe
- Print the schema of the dataframe
- Find people who are located in Paris
- Find the user who tweets the more
Conclusion
If you find better way/implementation, do not hesitate to send a pull request or open an issue on github.
Here are some useful links around Spark and its ecosystem: