
Dans les coulisses de Google BigQuery
###  |
1 – “Big Data” != “Hadoop”
Lorsque l’on pense à des technologies liées à la Big Data, on pense de suite à l’éco-système Hadoop, ou bien à Elasticsearch ou bien ces temps-ci beaucoup à Spark, mais il y a un “petit service” de Google qui ne fait pas beaucoup parler de lui mais qui peut tirer son épingle du jeu dans différents cas de figure.
Pour ma part, comme beaucoup d’entreprises, nous avons besoin de faire parler la donnée pour nos équipes en interne et nos clients, et la première architecture technique que nous avions mise en place reposait sur l’éco-système Hadoop avec un cluster sous Cloudera d’une dizaine de serveurs hébergée. Les performances étaient au rendez-vous mais le temps passé pour la maintenance et l’opérationnel était élevé. Lorsque BigQuery fut assez mature et répondait à nos besoins sur le papier, nous avions décider de créer une branche de notre projet et de tester cette nouvelle technologie de Google.
Résultats : une centaine d’euros d’économisés par mois pour l’électricité, les coût concernant l’opérationnel sur ce projet ont disparu et la facture de Google s’élève a environ 0,20$ par mois et des performances au final qui sont équivalentes avec celle du cluster Hadoop et qui répondent toujours au besoin des utilisateurs finaux.
2 – Histoire
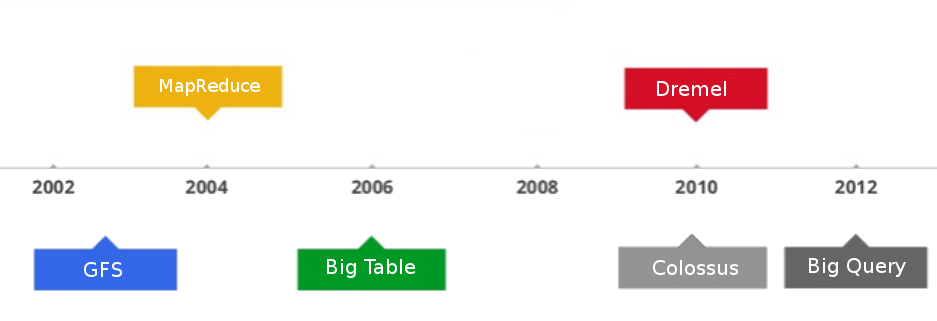
Comme beaucoup d’outils et de services, BigQuery a été conçu pour résoudre un problème.
Les ingénieurs de Google avaient du mal à suivre le rythme de croissance de leurs données. Le nombre d’utilisateurs de Gmail augmentait constamment et était de l’ordre de centaines de millions; en 2012, il y avait plus de 100 milliards de recherches Google effectuées chaque mois. Essayer de donner un sens à toutes ces données prenait un temps fou et était une expérience très frustrante pour les équipes de Google.
Ce problème de données a conduit l’élaboration d’un outil interne appelé Dremel, qui a permis aux employés de Google d’exécuter des requêtes SQL extrêmement rapides sur un grand ensemble de données. Selon Armando Fox, professeur d’informatique à l’Université de Californie à Berkley, “Dremel est devenu extrêmement populaire chez Google. Les ingénieurs de Google l’utilisent des millions de fois par jour.” Le moteur de requêtes Dremel a créé une façon de paralléliser l’exécution des requêtes SQL sur des milliers de machines. Dremel peut scanner 35 milliards de lignes sans un index en une dizaine de secondes.
Il existe deux technologies que Dremel utilise pour atteindre la lecture d’1 To de données en quelques secondes. Le premier est appelé Colossus : un système de fichier distribué et parallélisable développé à Google comme un successeur de Google File System (GFS). Le second est le format de stockage, appelé ColumnIO, qui organise les données d’une manière à ce que ce soit plus facile de les interroger.
En 2012, lors du Google I/O, Google a lancé publiquement BigQuery, qui a permis aux utilisateurs en dehors de Google de profiter de la puissance et la performance de Dremel.
3 – BigQuery, c’est quoi ?
Google BigQuery est une solution en mode SaaS (Software as a service) qui repose sur la plateforme de Cloud de Google et de ce fait de sa puissance de calcul.
Grâce à BQ on peut stocker, effectuer des requêtes et analyser des grands volumes de données : requêter des tables de plusieurs Tera Octets de données ne prend que quelques secondes.
Cette solution s’intègre bien avec Google App Engine mais également avec d’autres plateformes.
Techniquement, le service BigQuery est juste un serveur qui accepte les requêtes HTTP et renvoie les réponses au format JSON. Il communique avec Dremel, le moteur de requêtes qui communique avec Colossus.
4 – Pourquoi utiliser BigQuery ?
- Sécurisé
- SLA 99.9% (https://cloud.google.com/bigquery/sla)
- Infrastructure de Google
- Pas de coût de serveurs, d’opération et de maintenance
- Moins complexe que l’éco-système Hadoop
- BigQuery SQL
- Scalabilité
- Rapide
- “Pay only for what you use”
- Requêtes synchrones et asynchrones
5 – Inconvénients/Limitations
- “Append-only tables” : on ne peut pas modifier (UPDATE) ou supprimer (DELETE) des entrées dans une table, seulement y ajouter des entrées
- Des latences réseau peuvent se produire
- Performant sur des énormes tables (Go, To), moins sur de petites tables
6 – Quotas
* Requêtes : 20 000 requêtes par jour (et jusqu’à 100 To de données).
* Chargement/Upload de donnée :
- Limite quotidienne : 1000 jobs de chargement par table par jour, 10 000 jobs de chargement par projet et par jour (y compris les échecs pour les deux).
- 1000 fichiers max par job de chargement.
- Taille maximum par type de fichier :
 * Streaming : 100 000 lignes insérées par seconde par table maximum.
* Streaming : 100 000 lignes insérées par seconde par table maximum.
A noter que toutes les données qui sont en cache, ne sont pas comptées dans les quotas.
Vous pouvez voir la liste complète des quotas si cela vous intéresse.
7 – Coûts
Les utilisateurs de BigQuery sont actuellement facturés pour deux choses : le stockage et les requêtes. Les deux coûts sont proportionnels à la taille des données.
Importer des données via un fichier CSV ou JSON est gratuit.
Voici le modèle des coûts décrit de manière détaillée :

Les prix sont sujets à changement donc veuillez vous tenir informés sur le site officiel de BigQuery : https://developers.google.com/bigquery/pricing.
8 – Architecture technique
Pour comprendre comment BigQuery peut-il être aussi performant sur d’énormes tables, il faut se pencher sur son architecture technique.
Comme on l’a déjà vu ci-dessus, BigQuery est une implémentation externe de Dremel. Pour essayer de comprendre en quelques mots comment fonctionne BigQuery, il faut connaître les deux technologies de base de Dremel :
1. Base de Données orientée colonne
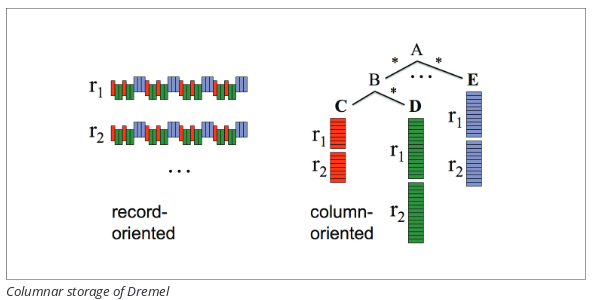 Source : livre Google BigQuery Analytics
Source : livre Google BigQuery Analytics
Dremel utilise BigTable et ColumnIO (des bases de données orientées colonne) et stocke les données sous forme de colonne. Grâce à cela, on ne charge que les colonnes dont on a vraiment besoin.
Dremel stocke les enregistrements par colonne sur des volumes de stockage différents, alors que les bases de données traditionnelles stockent normalement l’ensemble des données sur un seul volume. Cela permet un taux de compression très élevé.
2. Architecture en arbre
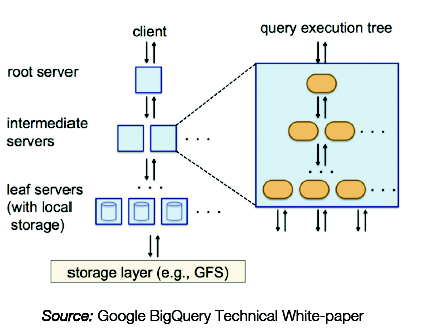
Ce type d’architecture est utilisé pour dispatcher les requêtes et agréger les résultats à travers des milliers de machines en quelques secondes.
9 – Composants

Source : livre Google BigQuery Analytics
- Projects
Toutes les données dans BigQuery sont stockées dans des projets. Un projet est identifié par un ID unique ainsi qu’un nom. Il contient la liste des utilisateurs autorisés, les informations concernant la facturation et l’authentification à l’API.
- Dataset
Les tables sont groupées par dataset qui peut être partagé à d’autres utilisateurs. Un dataset peut contenir une ou plusieurs tables.
- Table
Les tables sont représentées comme ceci :
Pour comprendre cette règle de nommage, regardons de plus prés une requête SQL :
SELECT message FROM [meetup:logs.latest]
le champ message est sélectionné de la table latest qui est dans le dataset logs qui est dans le projet meetup.
Lorsque l’on créer une table il faut définir son schéma.
Exemple de schéma :
word:STRING,wordcount:INTEGER,corpus:STRING,corpus_date:INTEGER

Type de données possible : string, integer, float, boolean, timestamp et record (nested / repeatable).
- Jobs
Toutes les opérations asynchrones que BigQuery effectue sont faites par les jobs (chargement, insertion de ligne, exécution d’une requête).
10 – Moyens d’accès
Pour communiquer avec BigQuery il existe plusieurs moyens :
- Via la Google API Console (Web UI : https://bigquery.cloud.google.com/)
Cette interface permet d’effectuer la plupart des opérations dans l’API : lister les tables disponibles, afficher leur schéma et leurs données, partager des dataset avec d’autres utilisateurs, charger des données et les exporter vers Google Cloud Storage.
La console de Google est très pratique lorsque l’on veut exécuter/tester/fine-tuner (optimiser) des requêtes.
En quelques clics on crée sa requête, on l’exécute et on obtient les résultats en quelques secondes.
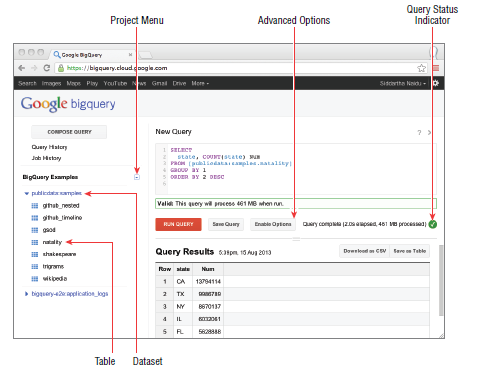 Source : livre Google BigQuery Analytics
Source : livre Google BigQuery Analytics
Si vous n’avez aucun projet de créé avec Google BigQuery d’activé et que vous souhaitez accéder à la Google console, vous pouvez cliquer sur le bouton “Essai gratuit”.
- En ligne de commande (bq command line tool) :
Si l’on souhaite par exemple ajouter une colonne dans une table, en ligne de commande c’est possible.
0. Pré-requis : vous devez installer ou avoir Python d’installé sur votre machine.
Puis vous devez vous authentifiez :
gcloud auth login
1. Il suffit de récupérer le schéma de la table :
bq –format=prettyjson show yourdataset.yourtable > table.json
2. Il faut maintenant modifier le fichier, tout supprimer excepté le schema (garder [ { “name”: “x” … }, … ]) et ajouter la nouvelle colonne a la fin par exemple.
3. Mettre à jour le schema de sa table :
bq update yourproject.yourtable table.json
- Via les APIs :
- Il existe une dizaine de librairies clientes qui sont mises à disposition par Google. Elles sont disponible pour Java, Python, PHP, Ruby, .NET …
- Et bien entendu il existe une API de type REST.
A noter que les APIs utilisent l’API d’authentification OAuth2.
- Via des connecteurs JDBC (Starschema)
- Via le connecteur Excel
11– Chargement des données
Il existe deux moyens pour charger des données dans une table :
- Soit, via la Google console, lors de la création de la table on définit une source de donnée. Ce peut être un fichier au format CSV, JSON ou AppEngine Datastore, que vous uploadez ou que vous importez du Google Cloud Storage.
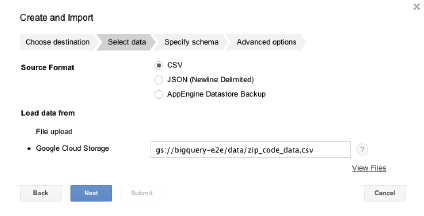
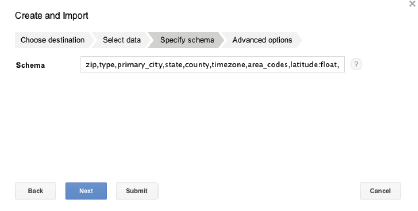
Puis il faut bien penser à définir le schéma de cette table :
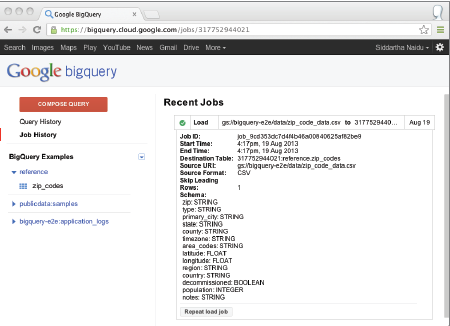
 Le job qui a procédé au chargement des données et à la création de la table a bien fonctionné :
Le job qui a procédé au chargement des données et à la création de la table a bien fonctionné :
* Soit, via l’API, on peut charger un fichier CSV ou JSON également ou bien insérer des entrées dans une table :
List rowList = new ArrayList(); rowList.add(new TableDataInsertAllRequest.Rows() .setInsertId(““+System.currentTimeMillis()) .setJson(new TableRow().set(“adt”, null)));
TableDataInsertAllRequest content = new TableDataInsertAllRequest().setRows(rowList); TableDataInsertAllResponse response = bigquery.tabledata().insertAll( PROJECT_NUMBER, DATASET_ID, TABLE_ID, content).execute(); System.out.println(“kind=”+response.getKind()); System.out.println(“errors=”+response.getInsertErrors()); System.out.println(response.toPrettyString());
12– BigQuery SQL
Les requêtes sont écrites en utilisant une variante de l’instruction SQL SELECT standard. BigQuery prend en charge une grande variété de fonctions telles que COUNT, les expressions arithmétiques, et les fonctions de chaîne. Vous pouvez consulter la page Query Reference pour tout savoir sur le langage de requête de BigQuery.
Tout comme le SQL standard, l’instruction SELECT s’écrit de cette manière :
SELECT expr1 [[AS] alias1] [, expr2 [[AS] alias2], …] [agg_function(expr3) WITHIN expr4] [FROM [(FLATTEN(table_name1|(subselect1)] [, table_name2|(subselect2), …)] [[INNER|LEFT OUTER|CROSS] JOIN [EACH] table_2|(subselect2) [[AS] tablealias2] ON join_condition_1 [… AND join_condition_N …]]+ [WHERE condition] [GROUP [EACH] BY field1|alias1 [, field2|alias2, …]] [HAVING condition] [ORDER BY field1|alias1 [DESC|ASC] [, field2|alias2 [DESC|ASC], …]] [LIMIT n] ;
A noter quelques fonctionnalités intéressantes de BigQuery SQL :
- TABLE_DATE_RANGE :
Au lieu de lister toutes les tables quotidiennes dans votre SELECT, comme ceci :
SELECT TIMESTAMP_TO_MSEC(rdt), cl, cid FROM myproject.MEETUP_20150317, myproject.MEETUP_20150318, myproject.MEETUP_20150319 WHERE rdt >= ‘2015-03-17 16:45:00’ AND rdt < ‘2015-03-19 10:50:00’ ORDER BY rk LIMIT 5001
Voici ce qu’il est possible de faire avec cette fonction de wildcard :
SELECT TIMESTAMP_TO_MSEC(rdt), cl, cid FROM (TABLE_DATE_RANGE(myproject.MEETUP_, TIMESTAMP(‘2015-03-17’), TIMESTAMP(‘2015-03-19’))) WHERE rdt >= ‘2015-03-18 16:45:00’ AND rdt < ‘2015-03-19 10:50:00’ ORDER BY rk LIMIT 5001
Lorsqu’il s’agit de faire un SELECT sur une liste de tables quotidiennes sur plusieurs jours/semaines/mois, imaginez le gain pour l’écriture de la requête et les performances avec cette fonction.
- REGEXP_MATCH :
Vous pouvez également utiliser des expressions régulières directement dans vos requêtes :
| SELECT TIMESTAMP_TO_MSEC(rdt), titi, tata FROM [myproject.mytable_20141108] WHERE cl=18 AND rdt >= ‘2014-11-07 23:00:00’ AND rdt < ‘2014-11-08 22:59:00’ AND REGEXP_MATCH(id, ‘(?i)^(123456789 | 55884772)$’) AND REGEXP_MATCH(bid, ‘(?i)^(7423456 | 3465465415)$’) ORDER BY tutu LIMIT 123 |
13 – Cas d’utilisation
Il existe plusieurs solutions pour visualiser les données qui sont stockées dans BigQuery.
-
Utiliser Google App Scripts pour écrire les requêtes et visualiser les résultats dans des graphiques dans Google Sheets. Si vous êtes intéressés par cette solution, je vous invite à lire ce tutoriel. Un module complémentaire existe sur le Chrome Store également mais je ne l’ai pas encore testé : OWOX BI BigQuery Reports.
-
Développer une application (web/mobile …) via les APIs et librairies clientes mises à disposition afin de visualiser les données avec l’API Google Charts par exemple.
Voici quelques exemples du rendu que l’on peut avoir :
 Source : http://bigquery-sensors.appspot.com/console
Source : http://bigquery-sensors.appspot.com/console
{kind=link}
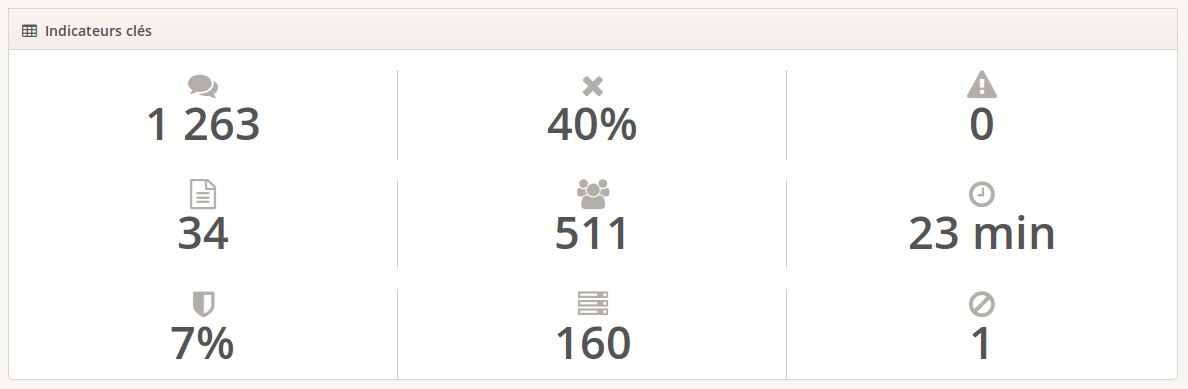
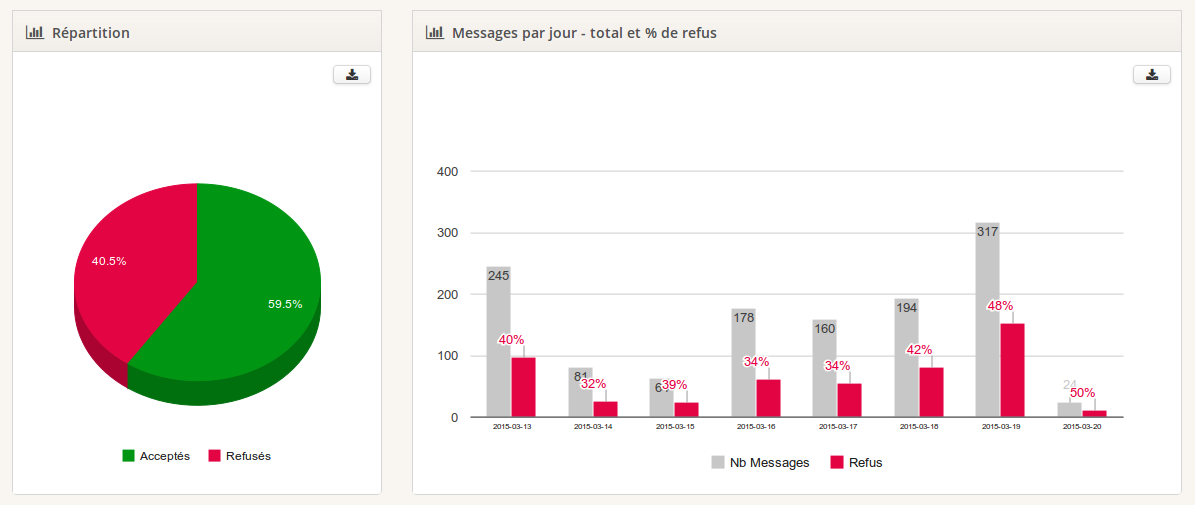 Source : Un des outils de reporting et de BI d’atchikservices.
Source : Un des outils de reporting et de BI d’atchikservices.
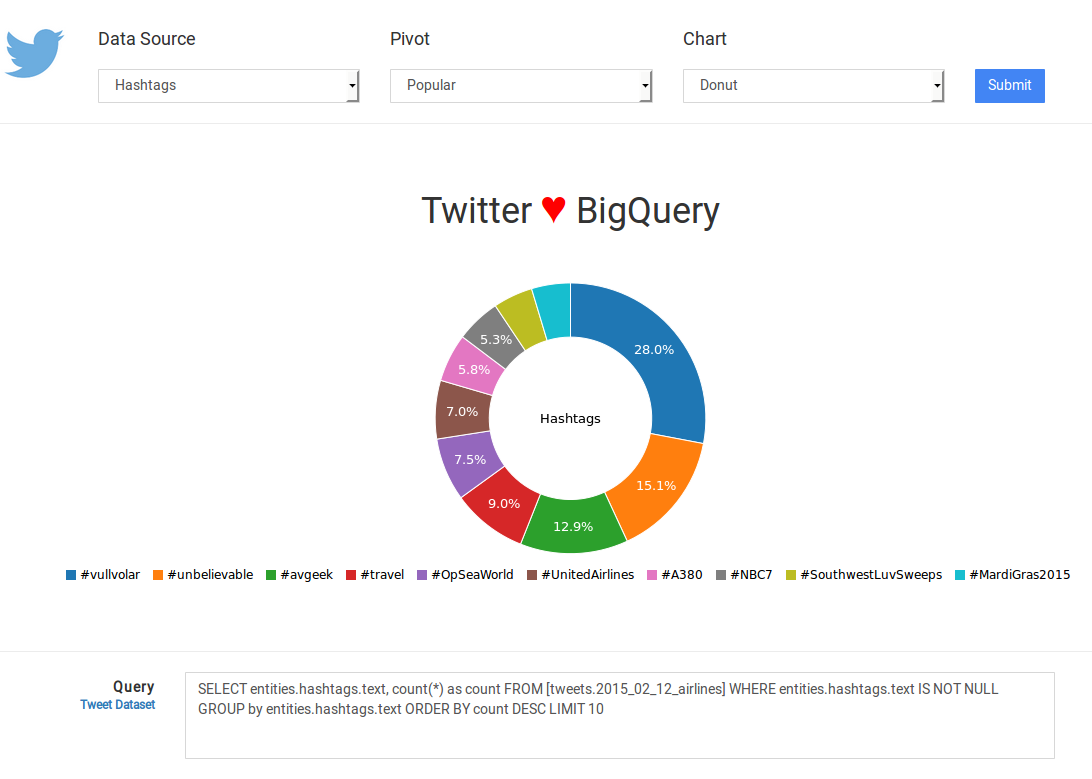 Source : Twitter for BigQuery.
Source : Twitter for BigQuery.
- Utiliser des outils tiers qui s’interconnectent très bien avec BQ :

14 – Conclusion
Je tenais à vous parler de Google BigQuery parce qu’il s’agit d’une techno que j’utilise au travail et qui ne fait pas assez parler d’elle à mon goût. Ce n’est pas une solution miracle, cela n’existe pas, mais elle peut répondre à un besoin donné.
Le fait de notamment pouvoir intérroger la base de données en SQL, c’est vraiment très pratique. En quelques secondes on peut exécuter sa requête sur la Web UI et obtenir un export en CSV.
A noter qu’une formation sur Google BigQuery sera donnée lors de Devoxx France 2015. Si cet article vous a donné envie d’en apprendre davantage à propos de BigQuery, inscrivez-vous !
Et vous, avez-vous des problématiques de Big Data, avez-vous déjà utilisé Google BigQuery ou prévu de le faire ?
EDIT:
Si vous voulez en savoir plus : https://fr.slideshare.net/aurelievache/google-bigquery-devfest-toulouse-2016